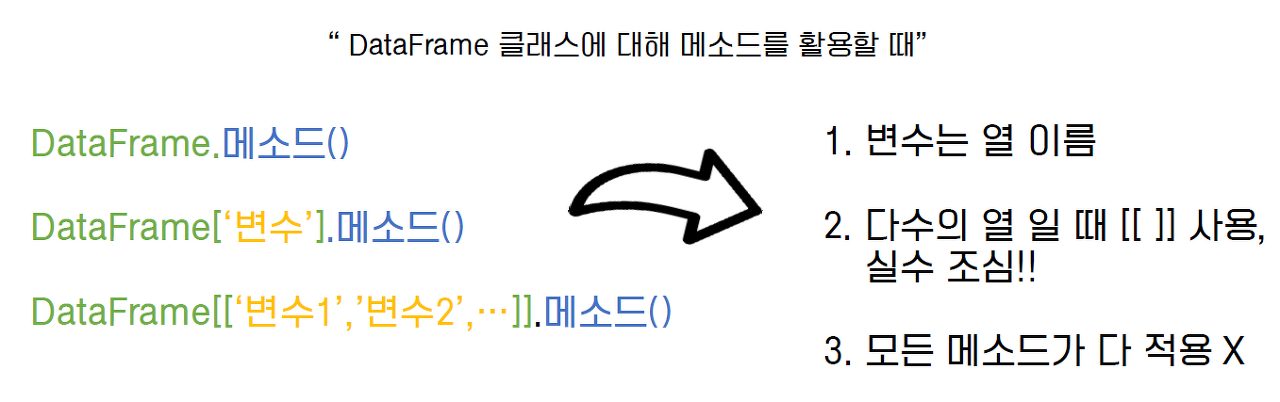
데이터 살펴보기(head(), tail())
import pandas as pd
# read_csv() 함수로 df 생성
df = pd.read_csv('./auto-mpg.csv', header = None)# df의 모양과 크기 확인 : (행의 개수, 열의 개수)를 투플로 반환
print(df.shape)
- 데이터프레임의 크기 확인 : DataFrame 객체.shape ⇒ 행의 개수와 열의 개수를 투플로 반환
# 데이터프레임 df의 내용 확인
print(df.info())
- 데이터프레임의 기본 정보 출력 : DataFrame 객체.info()
- 첫 행에 df의 클래스 유형
- 행 인덱스와 열에 대한 정보
- 각 열의 이름과 데이터 개수, 자료형
- 자료형과 메모리 사용량 표시
** 참고 : 판다스 자료형(data type)
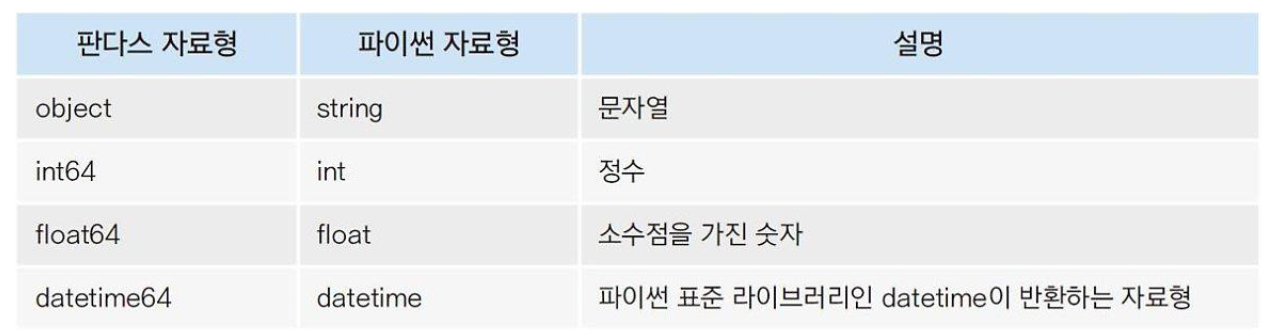
- info() 메소드 외 데이터프레임 클래스의 dtypes 속성을 활용하여 각 열의 자료형을 확인할 수 있다!
데이터 살펴보기(describe())
# 데이터프레임 df의 기술통계 정보 확인
print(df.describe())
print('\n')
print(df.describe(include = 'all'))

- 데이터프레임의 기술 통계 정보 요약 : DataFrame 객체.describe()
- 산술 데이터가 아닌 열에 대한 정보를 포함할 때는 include='all' 옵션 추가
- 고유값 개수, 최빈값, 빈도수에는 추가, 산술 데이터에는 NaN 값이 표시됨
df.describe(percentiles=[.1,.2,.3])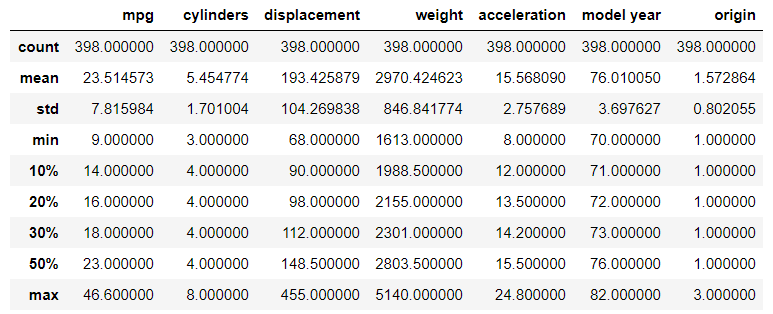
df.describe().astype('int')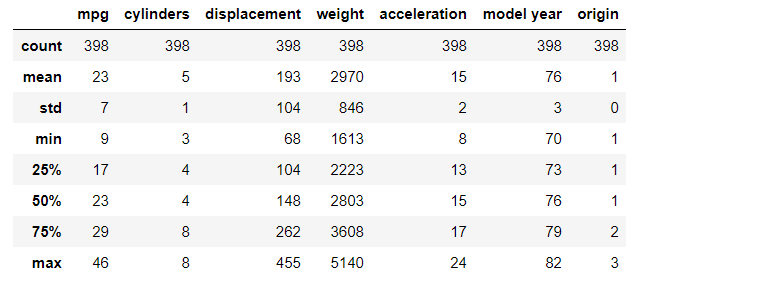
데이터 살펴보기(count(), value_counts())
# 데이터프레임 df의 각 열이 가지고 있는 원소 개수 확인
print(df.count())
- 열 데이터 개수 확인 : DataFrame 객체.count()
# 데이터프레임 df의 특정 열이 가지고 있는 고유값 확인
unique_values = df[0].value_counts()
print(unique_values)
통계 함수 적용(평균값)
# 통계 함수 적용(평균값)
# 평균값
print(df.mean())
print('\n')
print(df['mpg'].mean())
print(df.mpg.mean())
print('\n')
print(df[['mpg', 'weight']].mean())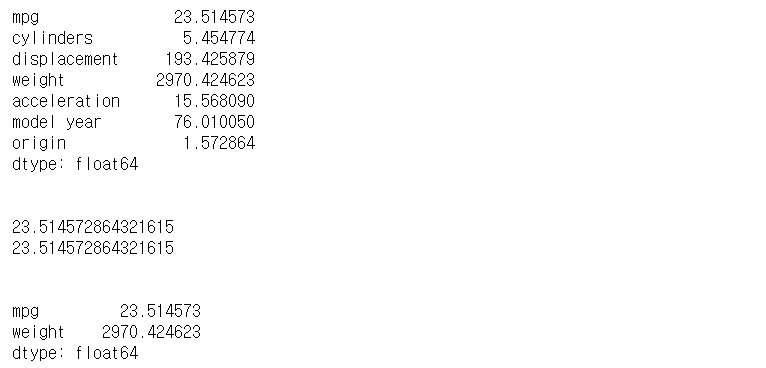
- 모든 열의 평균값 : DataFrame 객체.mean()
- 특정 열의 평균값 : DataFrame 객체['열 이름'].mean()
- 다른 통계 함수도 똑같이 적용됨
통계 함수 적용(중간값, 초대값, 최소값, 표준편차, 상관계수)
# 통계 함수 적용(중간값, 최대값, 최소값, 표준편차, 상관계수)
# 중간값
print(df.median())
print('\n')
print(df['mpg'].median())
# 최대값
print(df.max())
print('\n')
print(df['mpg'].max())
# 최소값
print(df.min())
print('\n')
print(df['mpg'].min())
# 표준편차
print(df.std())
print('\n')
print(df['mpg'].std())
# 상관계수
print(df.corr())
print('\n')
print(df[['mpg', 'weight']].corr())
불린 인덱싱 : 매우 편리한 데이터 필터링 방식
# 라이브러리 불러오기
import seaborn as sns
# titanic 데이터셋의 부분을 선택하여 데이터프레임 만들기
titanic = sns.load_dataset('titanic')
# age가 60 이상인 승객만 추출
titanic_boolean = titanic[titanic['age'] > 60]
titanic_boolean.head()
- 새롭게 타이타닉 데이터 셋을 DataFrame으로 로드한 뒤, 승객 중 나이가 60세 이상인 데이터를 추출
- [ ] 연산자 내에 불린 조건을 입력하면 불린 인덱싱이 진행
불린 인덱싱(예시, AND)
titanic[titanic['age'] > 60][['sex', 'age']].head(3)
titanic[(titanic['age'] > 60) & (titanic['pclass'] == 1) & (titanic['sex'] == 'female')]
cond1 = titanic['age'] > 60
cond2 = titanic['pclass'] == 1
cond3 = titanic['sex'] == 'female'
titanic[cond1 & cond2 & cond3]
불린 인덱싱(예시, OR)
titanic[cond1|cond2].head()
- &와 |가 같이 있을 때 &가 우선순위를 가짐
isin() 활용 : 특정 값을 지닌 행들을 추출
# isin() 메서드 활용
isin_filter = titanic['sibsp'].isin([3,4,5])
df_isin = titanic[isin_filter]
df_isin.head()
- 'sibsp'값이 3, 4, 5인 행들을 추출
- 추출하려는 값들로 만든 리스트를 전단
불린 인덱싱과 isin() 활용 비교
# 불린 인덱싱과 비교
mask3 = titanic['sibsp'] == 3
mask4 = titanic['sibsp'] == 4
mask5 = titanic['sibsp'] == 5
df_boolean = titanic[mask3|mask4|mask5]
df_boolean.head()
Query 함수 : 조건에 맞는 데이터를 추출
- 장점 : 가독성과 편의성이 뛰어남
- 단점 : .loc[]로 구현한 것보다 속도가 느림
<Query 함수의 여러 기능>
- 비교 연산자(==, >, ≥, <, ≤, ≠)
- in 연산자(in, ==, not in, ≠)
- 논리 연산자(and, or, not)
- 외부 변수(또는 함수) 참조 연산
- 인덱스 검색
Query 함수(비교 연산자(==, >, ≥, <, ≤, ≠))
# titanic 데이터셋의 부분을 선택하여 데이터프레임 만들기
titanic = sns.load_dataset('titanic')
str_expr = 'age == 65' # 나이가 65이다 (비교연산자 ==)
titanic_q = titanic.query(str_expr) # 조건 부합 데이터 추출
titanic_q
str_expr = "age >= 65" # 나이가 65이다 (비교연산지 >=)
titanic_q = titanic.query(str_expr) # 조건 부합 데이터 추출
titanic_q.head()
Query 함수(in 연산자(in, ==, not in. !=))
str_expr = "age in [65, 66]" # 나이가 65 또는 66이다 (소문자 in 연산)
# str_expr = "age == [65, 66]" # 위와 동일한 표현식이다
titanic_q = titanic.query(str_expr) # 조건 부합 데이터 추출
titanic_q
str_expr = "age not in [65, 66]" # 나이가 65 또는 66이 아니다 (소문자 in 연산)
# str_expr = "age != [65, 66]" # 위와 동일한 표현식이다
titanic_q = titanic.query(str_expr) # 조건 부합 데이터 추출
titanic_q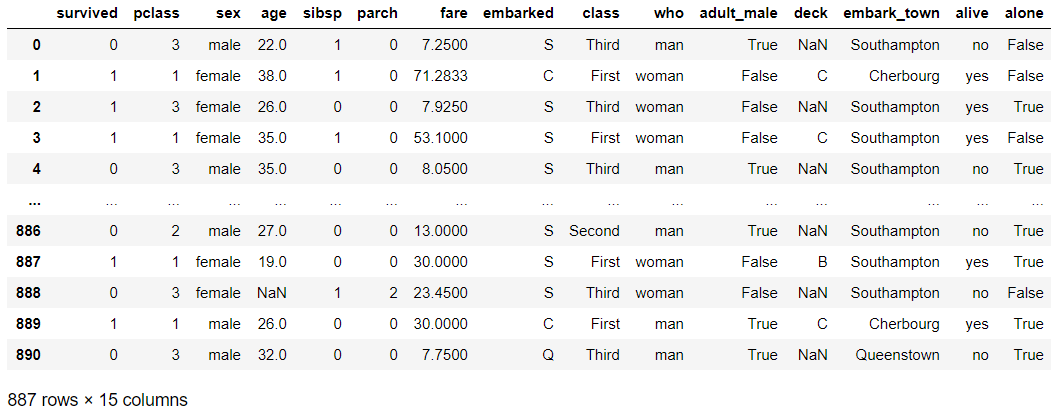
Query 함수(논리 연산자(and, or, not))
str_expr = "(age == 65) and (pclass >= 1)" # 나이가 65이고 pclass는 1 이상이다.
titanic_q = titanic.query(str_expr) # 조건 부합 데이터 추출
titanic_q.head()
str_expr = "(age == 65) or (pclass >= 1)" # 나이가 65이고 pclass는 1 이상이다.
titanic_q = titanic.query(str_expr) # 조건 부합 데이터 추출
titanic_q.head()
- and : 좌우 모두 참
- or : 좌우 중 하나
- not : 값의 반대
Query 함수(외부 변수(또는 함수) 참조 연산)
num_age = 35
str_expr = "age ==@num_age"
titanic_q = titanic.query(str_expr) # 조건 부합 데이터 추출
titanic_q.head()
num_age = 35
num_pclass = 2
str_expr = f"(age == {num_age}) and (pclass >= {num_pclass})"
titanic_q = titanic.query(str_expr) # 조건 부합 데이터 추출
titanic_q.head()
- 외부 변수명 또는 함수명 앞에 @를 붙여 사용
- f-string를 이용하여 str-expr를 만들 때 외부변수를 미리 참조
Query 함수 (인덱스 검색)
str_expr = "index >= 2" # 인덱스가 2 이상인 데이터
titanic_q = titanic.query(str_expr) # 조건 부합 데이터 추출
titanic_q.head()
- 인덱스 이름이 있다면 index 대신 인덱스 이름을 기입
- 인덱스 명이 칼럼 명과 겹친다면 칼럼 명으로 간주되어 칼럼으로 연산
'Python > 데이터 전처리' 카테고리의 다른 글
| 데이터프레임 연산(판다스/Pandas) (0) | 2022.04.11 |
|---|---|
| 데이터프레임 합치기(판다스/Pandas) (0) | 2022.04.07 |
| 데이터프레임 핸들링(판다스/Pandas) (0) | 2022.03.25 |
| 파이썬 기초 - for문, while문 (0) | 2022.03.25 |
| 파이썬 기초 - 조건문 (0) | 2022.03.25 |