Python/머신러닝
머신러닝 개요
강떡볶
2022. 4. 23. 21:09
머신러닝(Machine Learning)이란?
데이터에서 지식을 추출하는 작업으로 기계 스스로 데이터를 학습하여 서로 다른 변수 간의 관계를 찾아나가는 과정
- 기존의 접근 방식
- 스팸 메일의 일반적인 형태 파악
- 모든 패턴에 대한 탐지 알고리즘을 수동으로 작성
- 프로그램을 테스트하고 충분할 때까지 앞의 절차들을 반복
⇒ 모든 패턴을 수동으로 파악해야 함. 엄청난 양의 패턴을 모두 찾을 수는 없음
⇒ 프로그램이 너무 길고 복잡해여 유지하기가 어려움
- 하지만 머신러닝을 활용한다면?
- 프로그램이 짧아 유지하기 쉽고 정확도가 높음
- 새로운 패턴을 자동으로 찾아내고, 그에 맞춰 별도의 개입 없이 변화함
⇒ 일반적인 메일과 비교했을 때 스팸메일 속의 일반적이지 않은 패턴을 자동으로 발견해 냄
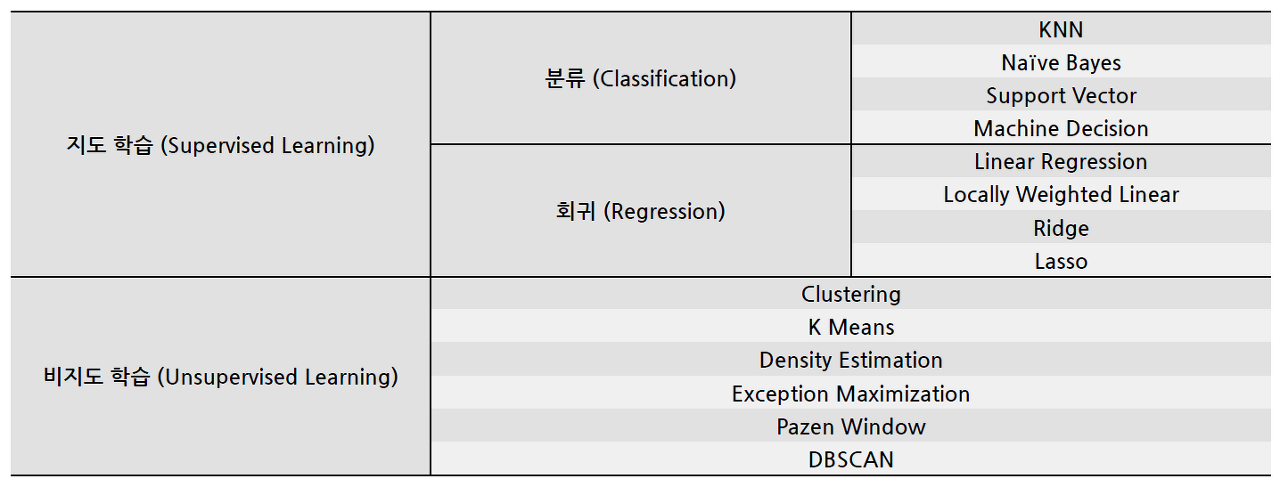
지도학습이란?
정답 데이터를 다른 데이터와 함께 컴퓨터 알고리즘에 입력하는 방식. 대표적으로 '분류'와 '회귀'
- 분류(Classification)
- 미리 정의된, 가능성 있는 여러 클래스 레이블 중 하나를 예측하는 것
- ex) 붓꽃 데이터를 통해 품종 분류
- 회귀(Regression)
- 훈련 데이터를 이용하여 연속적인 (숫자) 값을 예측하는 것
- ex) 집 평수와 가격 관계
⇒ 출력값의 '연속성' 여부로 분류와 회귀 구분 가능!
비지도학습이란?
정답 데이터 없이 컴퓨터 알고리즘 스스로 데이터로부터 숨은 패턴을 찾아내는 방식
- 군집(Clustering)
- 정답 라벨이 없어 비슷한 특징끼리 군집화하여 새로운 데이터에 대한 결과를 예측하는 방법. 라벨리 되어있지 않은 데이터로부터 패턴이나 형태를 찾아야 하기 때문에 난이도 ↑
- ex) 마케팅 캠페인을 위해 유사한 인구 통계나 구매 패턴을 가진 그룹으로 고객을 세분화
과대적합(Overfitting)이란?
모델이 train data에 너무 잘 맞아 일반성이 떨어지는 경우
- 가진 정보를 모두 사용해서 모델이 너무 복잡하고 train data 이외의 다른 변수에는 다응하기 힘듦.
- train data에서는 높은 정확도를 보이지만 test data에서는 높은 성능을 보여주지 못함.
해결 방법
- 더 많은 train data 수집하기
- 훈련 데이터 속의 noise 줄이기 ex) 아웃라이어 제거, 에러 수정
- 정규화 등을 통해 모델을 간소화
과소적합(Underfitting)이란?
모델이 너무 단순해서 test data의 내재된 구조를 학습하지 못하는 경우
- 집이 있는 사람은 모두 요트를 사려고 할 것이다?
- 데이터의 면면과 다양성을 잡아내지 못해 test set뿐만 아니라 train set에도 잘 맞지 않음.
해결 방법
- 더 많은 파라미터를 가진 강력한 모델 선택하기
- Feature engineering을 통해 학습 알고리즘에 더 적절한 피처들 제공하기
- 모델의 제약 줄이기 ex) 정규화된 하이퍼파라미터 값 줄이기
모델이 복잡해지면 발생하는 문제
모델을 복잡하게 할 수록 train data 정확하게 예측 → 좋은 것 아닐까?
너무 복잡해지면 train set의 각 data point에 너무 민감함→ 새로운 data에 잘 일반화되지 못함
