Python/데이터 전처리
데이터프레임 핸들링(판다스/Pandas)
강떡볶
2022. 3. 25. 22:29
데이터프레임(행 인덱스/열 이름 설정)
# 데이터프레임(행 인덱스/열 이름 설정)
# 행 인덱스/열 이름을 지정하여 데이터프레임 만들기
df = pd.DataFrame([[15, '남', '덕영중'], [17, '여', '수리중']],
index = ['준서', '예은'],
columns = ['나이', '성별', '학교'])
#행 인덱스, 열 이름 확인하기
print(df)
print('\n')
print(df.index)
print('\n')
print(df.columns)
- pd.DataFrame(2차원 배열, index = 행 인덱스 배열, columns = 열 이름 배열)
- 실행 결과 리스트가 행으로 변환
- 행 인덱스 접근 ⇒ df.index
- 열 인덱스 접근 ⇒ df.columns
# 행 인덱스, 열 이름 변경하기
df.index = ['학생1', '학생2']
df.columns = ['연령', '남녀', '소속']
print(df)
print('\n')
print(df.index)
print('\n')
print(df.columns)
# 열 이름 중 '나이'를 '연령'으로, '성별'을 '남녀'로, '학교'를 '소속'으로 바꾸기
df.rename(columns={'나이':'연령', '성별':'남녀', '학교':'소속'}, inplace = True)
# df의 행 인덱스 중에서 '준서'를 '학생1'로, '예은'을 '학생2'로 바꾸기
df.rename(index={'준서':'학생1', '예은':'학생2'}, inplace=True)
# df 출력 (변경 후)
df
** 위, 아래 두 방법 다 변경할 수 있으나 아래의 경우는 일부분의 행 인덱스와 열 이름 변경도 가능
데이터프레임(행 삭제)
# DataFrame() 함수로 데이터프레임 변환, 변수 df에 저장
exam_data = {'수학' : [ 90, 80, 70], '영어' : [ 98, 89 , 95],
'음악' : [ 85, 95 ,100], '체육' : [ 100, 90 ,90]}
df = pd.DataFrame(exam_data, index = ['서준', '우현', '인아'])
print(df)
print('\n')
# 데이터프레임 df를 복제하여 변수 df2에 저장. df2의 1개 행(row)을 삭제
df2 = df[:]
df2.drop('우현', inplace = True)
print(df2)
print('\n')
# 데이터프레임 df를 복제하여 변수 df3에 저장. df3의 2개 행(row)을 삭제
df3 = df[:]
df3.drop(['우현', '인아'], axis = 0, inplace = True)
print(df3)
- 행 삭제 : DataFrame 객체.drop(행 인덱스 또는 배열, axis=0(행 삭제))
- drop() 메소드는 기존 객체를 변경하지 않음
- 원본 객체를 변경하기 위해서는 inplce=True 옵션을 추가
데이터프레임(열 삭제)
# 데이터프레임 df를 복제하여 변수 df4에 저장. df4의 1개 열(column)을 삭제
df4 = df[:]
df4.drop('수학', axis = 1, inplace = True)
print(df4)
print('\n')
# 데이터프레임 df를 복제하여 변수 df5에 저장. df5의 2개 열(column)을 삭제
df5 = df [:]
df5.drop(['영어', '음악'], axis = 1, inplace = True)
print(df5)
- 열 삭제 : DataFrame 객체.drop(열 이름 또는 배열, axis=1)
- drop() 메소드는 기존 객체를 변경하지 않음
- 원본 객체를 변경하기 위해서는 ⇒ inplace=True 옵션을 추가
데이터프레임 (행 선택)
# 행 인덱스를 사용하여 행 1개를 선택
label1 = df.loc['서준'] # loc 인덱서 사용
position1 = df.iloc[0] # iloc 인덱서 사용
print(label1)
print('\n')
print(position1)
# 행 인덱스를 사용하여 2개 이상의 행 선택
label2 = df.loc[['서준', '우현']]
position2 = df.iloc[[0, 1]]
print(label2)
print('\n')
print(position2)
# 행 인덱스의 범위를 지정하여 행 선택
label3 = df.loc['서준' : '우현']
position3 = df.iloc[0:1]
print(label3)
print('\n')
print(position3)

데이터프레임(열 선택)
# '수학' 점수 데이터만 선택. 변수 math에 저장
math1 = df['수학']
print(math1)
print(type(math1))
print('\n')
- 열 1개 선택 : df[열1] or df.열1
- 시리즈 객체로 추출
# '음악', '체육' 점수 데이터를 선택. 변수 music_gym에 저장
music_gym = df[['음악', '체육']]
print(music_gym)
print(type(music_gym))
print('\n')
- 열 n개 선택 : df[[열1, 열2, ... , 열n]]
- 데이터프레임 객체로 추출
# '수학' 점수 데이터만 선택. 변수 math2에 저장
math2 = df[['수학']]
print(math2)
print(type(math2))
print('\n')
- 열 1개를 데이터프레임으로 추출 : df[['열1']]
데이터프레임(원소 선택)
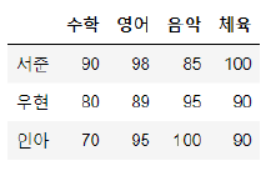
#데이터프레임 df의 특정 원소 1개 선택 ('서준'의 '음악' 점수)
a = df.loc['서준', '음악']
print(a)
b = df.iloc[0,2]
print(b)
1) 시리즈형
# 데이터프레임 df의 특정 원소 2개 이상 선택 ('서준'의 '음악', '체육' 점수)
c = df.loc['서준', ['음악', '체육']]
print(c)
d = df.iloc[0, [2, 3]]
print(d)
e = df.loc['서준', '음악':'체육']
print(e)
f = df.iloc[0, 2:]
print(f)
2) 데이터프레임형
# df의 2개 이상의 행과 열로부터 원소 선택 ('서준', '우현'의 '음악', '체육' 점수)
g= df.loc[['서준', '우현'], ['음악', '체육']]
print(g)
h = df.iloc[[0, 1], [2, 3]]
print(h)
i = df.loc['서준':'우현', '음악':'체육']
print(i)
j = df.iloc[0:2, 2:]
print(j)
데이터프레임(열 추가)
# 데이터프레임 df에 '국어' 점수 열(column)을 추가. 데이터 값은 80 지정
df['국어'] = 80
df
- 열 추가: DataFrame 객체['추가하려는 열이름'] = 데이터 값
데이터프레임(행 추가)
# 앞에서 만들었던 데이터 프레임 다시 만들기!
exam_data = {'이름': ['서준', '우현', '인아'],
'수학' : [ 90, 80, 70],
'영어' : [ 98, 89, 95],
'음악' : [ 85, 95, 100],
'체육' : [ 100, 90, 90]}
df = pd.DataFrame(exam_data)
df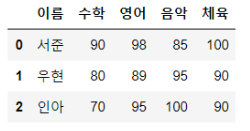
# 데이터프레임(행 추가)
df2 = df[:]
df2.loc[3] = 0
df2
# 새로운 행(row)을 추가 - 원소 값 여러 개의 배열 입력
df2.loc[4] = ['동규', 90, 80, 70, 60]
df2
- 행 추가 : DataFrame.loc['새로운 행 이름'] = 데이터 값(또는 배열)
- 데이터 값 입력 시 동일한 값이 입력됨
- 다른 값을 넣을 때 여러 개의 배열이 입력됨
- df.loc['새로운 행 이름'] = df.loc['기존 행 이름'] : 새로운 행에 기존 행 복사
데이터프레임(원소 값 변경)

# 데이터프레임 df의 특정 원소를 변경하는 방법: '서준'의 '체육' 점수
df.iloc[0][3] = 80
df
df.loc['서준']['체육'] = 90
df
df.loc['서준', '체육'] = 100
df
- 3가지 방법으로 한 개의 원소 값 변경 가능
- df.iloc[m][n] = 변경할 데이터 값
- df.loc['행 이름']['열 이름'] = 변경할 데이터 값
- df.loc['행 이름', '열 이름'] = 변경할 데이터 값
데이터프레임(여러 개 원소 값 변경)
# 데이터프레임 df의 원소 여러 개를 변경하는 방법: '서준'의 '음악', '체육' 점수
df.loc['서준', ['음악', '체육']] = 50
df
df.loc['서준', ['음악', '체육']] = 100, 50
df
- 여러 개의 원소 값 변경
- 데이터 값만 입력 시 동일한 값으로 변경
- 다른 값으로 변경 시 입력 순서대로 변경
데이터프레임(행, 열의 위치 바꾸기)

df = df.transpose()
df
df = df.T
df
인덱스 활용(특정 열을 행 인덱스로 설정)
exam_data = {'이름': ['서준', '우현', '인아'],
'수학' : [ 90, 80, 70],
'영어' : [ 98, 89, 95],
'음악' : [ 85, 95, 100],
'체육' : [ 100, 90, 90]}
df = pd.DataFrame(exam_data)
df
# 특정 열(column)을 데이터프레임의 행 인덱스(index)로 설정
ndf = df.set_index(['이름'])
ndf
# 인덱스 활용(특정 열을 행 인덱스로 설정)
# 딕셔너리를 정의
dict_data = {'c0' : [1,2,3], 'c1' : [4,5,6], 'c2' : [7,8,9], 'c3' : [10,11,12], 'c4' : [13,14,15]}
# 딕셔너리를 데이터프레임으로 변환, 인덱스를 [r0, r1, r2]로 지정
df = pd.DataFrame(dict_data, index = ['r0', 'r1', 'r2'])
print(df)
print('\n')
# 인덱스를 [r0, r1, r2, r3, r4]로 재지정
new_index = ['r0', 'r2', 'r3', 'r4']
ndf = df.reindex(new_index)
print(ndf)
print('\n')
# reindex로 발생한 NaN값을 숫자 0으로 채우기
new_index = ['r0', 'r1', 'r2', 'r3', 'r4']
ndf2 = df.reindex(new_index, fill_value = 0)
print(ndf2)
인덱스 활용(행 인덱스 초기화/행 인덱스 기준으로 데이터프레임 정렬)
ndf = df.reset_index()
print(ndf)
- 정수형 위치 인덱스로 초기화 : DataFrame 객체.reset_index()
# 내림차순으로 행 인덱스 정렬
ndf = df.sort_index(ascending = False)
print(ndf)
- 행 인덱스 기준으로 정렬 : DataFrame객체.sort_index()
# c1 열을 기준으로 내림차순 정렬
ndf = df.sort_values(by='c1', ascending = False)
print(ndf)- 특정 열 기준으로 정렬 : DataFrame 객체.sort_values(by='열 이름')
- *ascending=False 는 내림차순, 디폴트 값은 오름차순
열 순서 변경(리스트 이용)
# 라이브러리 불러오기
import seaborn as sns
# titanic 데이터셋의 부분을 선택하여 데이터프레임 만들기
titanic = sns.load_dataset('titanic')
df = titanic.loc[0:4, 'survived' : 'age']
df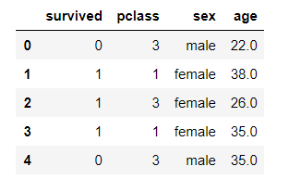
# 열 이름의 리스트 만들기
columns = list(df.columns.values) # 기존 열 이름
print(columns)
[STEP 1] 열 이름을 원하는 순서대로 정리 ⇒ 리스트 생성
[STEP 2] 데이터프레임에서 열을 다시 선택
1) sorted() : 알파벳 순
2) reversed() : 기존의 역순
3) List 생성 : 사용자 임의
# sorted() : 알파벳
columns_sorted = sorted(columns)
df_sorted = df[columns_sorted]
df_sorted
# reversed() : 기존 순서의 역순
columns_reversed = list(reversed(columns))
df_reversed = df[columns_reversed]
df_reversed
# List 생성 : 사용자의 임의(원하는 열만 뽑아서 추출하기)
columns_customed = ['pclass', 'sex', 'age', 'survived']
df_customed = df[columns_customed]
df_customed